
A regressão linear é o “Olá Mundo” dos modelos preditivos: simples de entender, rápida de treinar e poderosa para descobrir relações lineares entre variáveis. Neste post vamos aprender como fazer um modelo de regressão linear em Python.
A regressão linear é uma forma fundamental e amplamente utilizada de análise preditiva. Ela busca responder a duas questões essenciais: (1) quão bem um conjunto de variáveis preditoras consegue prever uma variável de resultado (dependente ou critério); e (2) quais variáveis específicas se destacam como preditoras significativas do resultado, e como seus coeficientes beta — que refletem magnitude e direção — influenciam esse resultado. Além disso, a regressão linear utiliza esses coeficientes para descrever a dinâmica entre uma variável dependente e uma ou mais variáveis independentes.
Preparando o Ambiente Virtual
Antes de começar o nosso código, vamos criar um ambiente virtual. Se você já tem um ambiente pronto e quer utilizá-lo, tudo bem. Somente ativá-lo.
# para mac ou linux
source <nome do seu ambiente>/bin/activate
# para windows
<nome do seu ambiente>\Scripts\activate
Se ainda tiver alguma dúvida de como criar e ativar o seu ambiente, você pode ler mais aqui.
Importando os Dados
Vamos começar a importar os pacotes necessários para este projeto.
import pandas as pd
Pandas é uma biblioteca Python de código aberto amplamente usada para análise e manipulação de dados. Ela oferece estruturas de dados poderosas e flexíveis — principalmente Series e DataFrames — projetadas para tornar o trabalho com dados estruturados intuitivo e eficiente.
Próximo, precisamos importar os dados que vamos usar. Nesse caso, eu criei uma planilha eletrônica com duas colunas. Uma mostrando a idade e a outra o salário anual.
dados = pd.read_excel("idade_salario.xlsx")
dados.head()
Antes de importar, tenha certeza que a spreadsheet está no mesmo arquivo onde o seu Jupyter Notebook está. Caso contrário, você terá que colocar o local inteiro.
O comando final exibe as primeiras cinco linhas do arquivo.
Vantagens do Pandas para Excel
- Leitura automática de formatos Excel (.xlsx, .xls)
- Conversão inteligente de tipos de dados
- Facilidade de manipulação posterior
Preparando os Dados para o Modelo Linear
Antes de criar nosso modelo, precisamos preparar os dados adequadamente:
X = dados["idade"]
y = dados["salario_anual"]
# Reshape dos dados para compatibilidade com sklearn
reshaped_X = X.values.reshape(-1, 1)
Por que o Reshape?
O scikit-learn espera que os dados de entrada tenham formato bidimensional. O reshape(-1, 1) transforma nosso array unidimensional em uma matriz, com:
- -1: Número automático de linhas
- 1: Uma coluna
Construindo o Modelo de Regressão Linear
Antes de criar o modelo, vamos importar os pacotes matemáticos necessários.
from sklearn.linear_model import LinearRegression
Agora vamos criar e treinar nosso modelo:
# Criando o modelo
modelo = LinearRegression()
# Treinando o modelo
modelo.fit(reshaped_X, y)
# Avaliando a performance
score = modelo.score(reshaped_X, y)
print(f"R2 Score: {score:.4f}")
Interpretando o R² Score
O R² (coeficiente de determinação) indica quanto da variabilidade dos dados é explicada pelo modelo. No nosso caso, obtivemos aproximadamente 0.7516, significando que o modelo explica cerca de 75% da variação nos salários baseado na idade.
Fazendo Predições
Com o modelo treinado, podemos fazer predições:
# Gerando predições
resultado = modelo.predict(reshaped_X)
Essas predições nos mostram os valores de salário que o modelo estima para cada idade em nosso dataset.
Visualização dos Resultados
A visualização é crucial para entender nossos dados e validar o modelo:
import matplotlib.pyplot as plt
plt.scatter(X, y)
Podemos também fazer o gráfico um pouco maior e adicionar rótulos. Também vamos fazer uma linha vermelha para nos mostrar as nossas predições.
plt.xlabel("Idade")
plt.ylabel("Salário")
plt.scatter(X, y)
plt.plot(X, resultado, color="red")
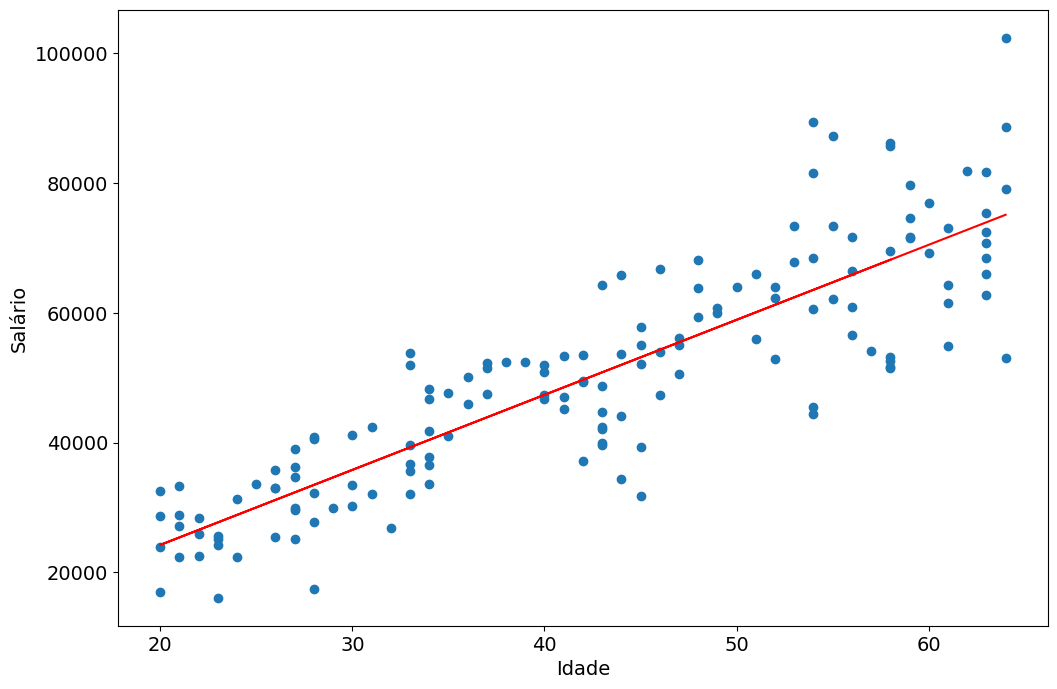
Insights e Conclusões
O que aprendemos com os dados?
- Correlação Positiva: Existe uma relação clara entre idade e salário
- Modelo Eficaz: Com R² de 0.75, o modelo tem boa capacidade preditiva
- Linearidade: A relação segue aproximadamente um padrão linear
Conclusão
A automação do Excel com Python oferece possibilidades incríveis para análise de dados. Com apenas algumas linhas de código, conseguimos criar um modelo de regressão linear e mais:
- Ler dados diretamente do Excel
- Criar um modelo preditivo
- Visualizar resultados de forma profissional
- Obter insights valiosos sobre nossos dados
Este é apenas o começo do que é possível fazer com Python na análise de dados. A combinação de pandas, scikit-learn e matplotlib fornece uma base sólida para projetos mais complexos de ciência de dados.
Comentários (0)
Seja o primeiro a comentar!
Deixe um comentário