As expressões regulares (regex) é uma ferramenta para trabalhar com padrões em textos. Com elas você pode procurar, validar, extrair, ou substituir informações de formas extremamente flexíveis. Nesse artigo, vamos explicar como funciona o regex em Python, desde os conceitos básicos até exemplos práticos.
Se você está apenas começando em Python, deve estar se perguntando o que é regex, como é usado, e porque aprender. Vamos abranger tudo isso nesse post aqui.
Lembre-se, isso é só uma introdução à esse método. As possibilidades aqui são infinitas.
O que é Regex?
Regex, ou como já falamos, expressões regulares, é uma sequência de caracteres (strings) que definem um padrão de pesquisa para encontrar ou manipular texto.
É uma ferramenta poderosa, usada em programação e ciência de dados para validar e substituir padrões específicos em cadeias de caracteres.
Por exemplo \d{3}-\d{2}-\d{4} vai encontrar também como 123-45-6789. Não necessariamente os números exatos, mas o padrão em que os números se encontram.
Outro exemplo [1]+@[A-Za-z0-9.-]+.[A-Za-z]{2,}$, isso valida um e-mail.
Regex permite automatizar tarefas de manipulação de texto, economizando tempo e esforço.
Por que Usar Regex em Ciência de Dados?
O regex é uma ferramenta muito útil, para muitas funções no ramo da ciência de dados. É indispensável para limpeza e pré--processamento de dados textuais. Também é muito útil para a extração de informações e validação de dados.
Vamos trabalhar um pouquinho com essa ferramenta?
Metacaracteres Essenciais
Então vamos entender um pouco mais.
Se você não entendeu ainda, não tem problema, vamos dar uns exemplos bem práticos.
Configurando o Ambiente
Vamos criar o ambiente para trabalhar com Python. Já cria o seu ambiente virtual e inicia o Jupyter. E vamos começar com uma coisa bem simples.
Primeiro vamos importar o pacote do regex.
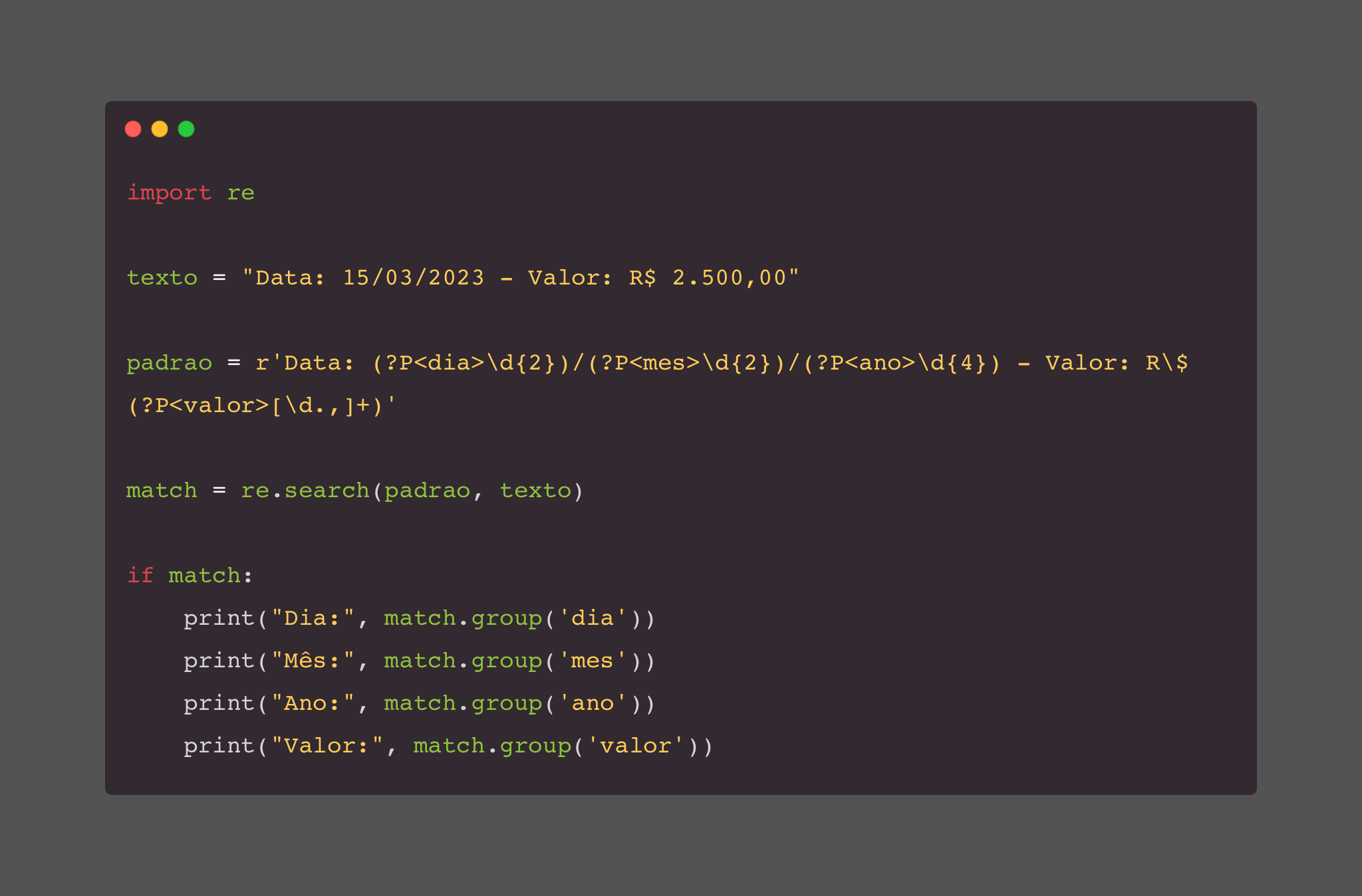
import re
texto = "Data: 15/03/2023 - Valor: R$ 2.500,00"
padrao = r'Data: (?P<dia>\d{2})/(?P<mes>\d{2})/(?P<ano>\d{4}) - Valor: R\$ (?P<valor>[\d.,]+)'
match = re.search(padrao, texto)
if match:
print("Dia:", match.group('dia'))
print("Mês:", match.group('mes'))
print("Ano:", match.group('ano'))
print("Valor:", match.group('valor'))
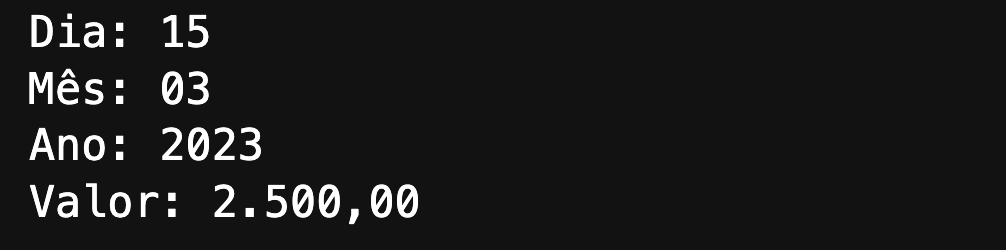
Vamos explicar passo a passo como fazer isso.
No texto queremos encontrar informações específicas como as datas 15/03/2023 e o valor R$ 2.500,00. No nosso código acima estamos capturando esses dados separadamente (dia, mês, ano e valor).
Deixa eu explicar passo a passo.
r'...' - Raw String
- O r antes da string significa "raw string"
- Evita problemas com caracteres de escape ()
- Em regex, usamos muito , então raw strings facilitam a vida
Data: - Texto Literal
- Busca exatamente o texto "Data: " (incluindo o espaço)
- Caracteres normais são interpretados literalmente
(?P\d{2}) - Grupo Nomeado
- (?P
...) é a sintaxe para criar um grupo nomeado é o nome que damos ao grupo - \d{2} significa "exatamente 2 dígitos"
- Captura o dia e permite acessá-lo pelo nome "dia"
/ - Caractere Literal
- Busca literalmente o caractere "/"
(?P\d{2}) - Outro Grupo Nomeado
- Similar ao dia, captura exatamente 2 dígitos para o mês
- Acessível pelo nome "mes"
/(?P\d{4})
- Mais uma barra literal seguida de grupo nomeado
- \d{4} = exatamente 4 dígitos para o ano
- Valor: R$ - Texto Literal com Escape
- Espaço, hífen, "Valor: R" são literais
- $ - o cifrão precisa de escape porque $ tem significado especial em regex (fim da string)
(?P[\d.,]+) - Grupo para Valor Monetário
- [\d.,] é uma classe de caracteres que permite:
\d = qualquer dígito (0-9) . = ponto (para milhares: 1.250) , = vírgula (para decimais: 50,25)
- + = uma ou mais ocorrências
- Captura valores como "1.250,50", "2500", "999,99"
Exemplos Práticos
Validando e-mails
email = "joao.silva@gmail.com"
padrao = r'^[\w\.-]+@[\w\.-]+\.\w{2,}$'
print(bool(re.match(padrao, email)))

Extraindo Números de um Texto
texto = "O pedido 123 custou R$ 456,00, entregue no dia 07/08/2025."
números = re.findall(r'\d+', texto)
print(numeros)

O resultado nesse caso são somente os números pois usamos o comando \d.
Validando telefones
telefone = "(11) 98888-7777"
padrao = r'^\(\d{2}\)\s9\d{4}-\d{4}$'
print(bool(re.match(padrao, telefone)))
Conclusão
O regex é uma função para molde e muito usada para determinar padrões. Isso é especialmente útil em ciência de dados. É importante lembrar que uma habilidade se aprimora com a prática. Comece com padrões simples e vá evoluindo gradualmente para casos mais complexos.
A-Za-z0-9._%+- ↩︎
Comentários (0)
Seja o primeiro a comentar!
Deixe um comentário