
Quando descobri que podia puxar dados da internet para estudar e criar máquinas de aprendizagem, achei isso demais. Nesse post vamos começar a aprender como fazer um web scraping com dados de futebol.
Nesse post vamos coletar informação de um website que mostra a tabela dos jogos desse ano do campeonato brasileiro. Com a informação que colhermos podemos usar para várias análises e fazer algumas previsões de quem vai ganhar os próximos jogos.
É importante lembrar que estamos no mundo dos esportes, e não existe previsão nenhuma que tenha um nível de confiança alta. Quando estamos lidando com pessoas, é muito difícil de prever o que poderá acontecer. Existem muitas variáveis que fazem uma análise robusta, quase impossível.
Por exemplo, o desempenho de um jogador pode ser afetado por algo que não estamos avaliando. Uma briga com a esposa, o com o técnico, uma discussão com o time antes de entrar em campo. Tudo isso pode causar mudanças imprevisíveis.
O que é Web Scraping?
O web scraping é uma raspagem ou extração de dados de sites. Esse processo envolve o uso de software para coletar informações de páginas web e transformá-las em um formato mais estruturado e útil para análise ou outras finalidades.
Web Scraping é Legal?
A legalidade de web scraping é sempre desafiada. Para ser sincero, sou bem leigo em assuntos legais.
Eu fiz uma pesquisa na internet para entender a legalidade disso. Infelizmente, não tem uma resposta clara para isso. Mas posso dizer o seguinte: estamos fazendo isso para uso pessoal. E geralmente uso pessoal não tem muitos problemas.
Também dei uma pesquisada nos termos de serviço e o site permite a extração de dados se não interferir com os serviços. No caso estamos fazendo uma coisa bem simples e não haverá nenhuma interferência a nenhum serviço.
Ferramentas para Esse Trabalho
Bem, as ferramentas que vamos usar para completar esse trabalho são as seguintes:
- Firefox (browser) ou Chrome
- Jupyter Notebook
- BeautifulSoup (pacote de python)
- Pandas (pacote de python)
Se tiver alguma dúvida de como instalar algum desses pacotes, pode sempre consultar outros posts aqui nesse blog. Temos bastante informação que explica como fazer tudo.
Vamos começar criando um ambiente virtual e instalando o Jupyter. Se você é familar com as ferramentas pode usar também o Spyder.
Web Scraping Tabela de Jogos do Campeonato Brasileiro
Você já deve estar se perguntando para que queremos esses dados. Bem, vamos usar pra fazer análises. Podemos fazer coisas simples, como verificar a probabilidade de um time ganhar ou perder. Algo até mais simples é ver quantos jogos um time perdeu em casa.
Aqui está a nossa tabela:
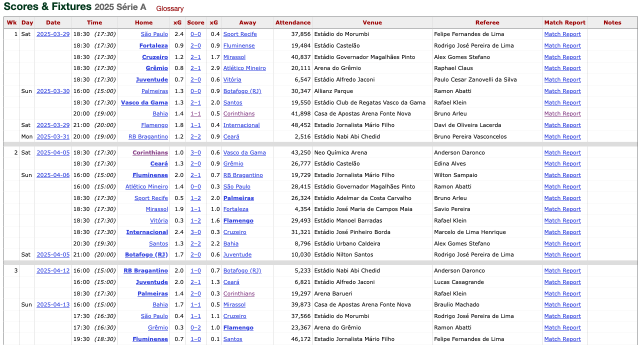
Você pode observar que há jogos que ainda não tem resultados, pois ainda não aconteceram. Vamos pegar esses jogos também, pois poderemos fazer a nossa probabilidade.
Instalando e Importando os Pacotes Necessários
Bora começar esse código.
O primeiro passo é importando os pacotes. Se por acaso não tiver algum dos pacotes, você pode instalar diretamente da célula do Jupyter. Não precisa abrir o terminal nem nada. Simplesmente faz o seu pip e o nome do pacote.
pip install bs4
pip install cloudscraper
Assim que tiver tudo instalado, é só importar.
from bs4 import BeautifulSoup
import cloudscraper
import pandas as pd
Iniciando o Beautiful Soup
Há várias ferramentas para extrair de websites. Eu já usei várias. Mas, nesse caso, vamos usar o Beautiful Soup. Na verdade, essa é uma ferramenta das mais comuns para esse tipo de projeto. É fácil de usar e mais fácil ainda de formatar as estruturas.
# o site que estamos pegando os dados
url = "https://fbref.com/en/comps/24/schedule/Serie-A-Scores-and-Fixtures"
# iniciando o scraper
scraper = cloudscraper.create_scraper()
dados = scraper.get(url).text
soup = BeautifulSoup(dados, 'html.parser')
O soup, se você correr essa célula verá que os dados já estão salvos no seu kernel. Por isso que o Jupyter Notebook é a melhor ferramenta para fazer isso.
Comece o restante em outra célula. Se caso ocorrer erros e precisar correr novamente, isso vai ser local. Em outras palavras, o seu código não vai buscar os resultados no site mais, pois estão salvos aqui. Isso é ideal porque se visitar o site várias vezes, podem te bloquear.
Achando a Tabela
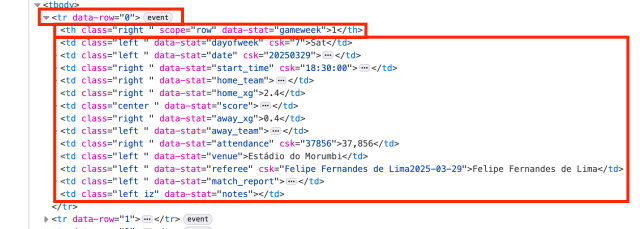
Nessa parte, vamos precisar ir para o Firefox. Na tabela dos resultados, clique com o botão direito e selecione o inspecionar.
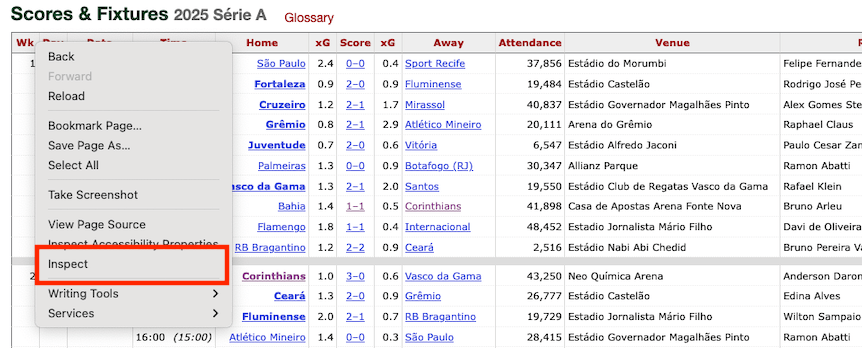
Isso vai abrir um painel dentro do Firefox. Você vai procurar esta linha aqui:

A única coisa que você quer dessa linha é o id da tabela, que se encontra aqui:

Vamos agora falar para o Python que isso é o que queremos.
tabela = soup.find('table', {'id':'sched_2025_24_1'})
Criando o Cabeçalho
Agora já temos a tabela separada, vamos trabalhar com os dados da tabela. Pode observar que em html, o cabeçalho é sempre ``. No seu Firefox, quando colocar o mouse no elemento, mostrará na página.
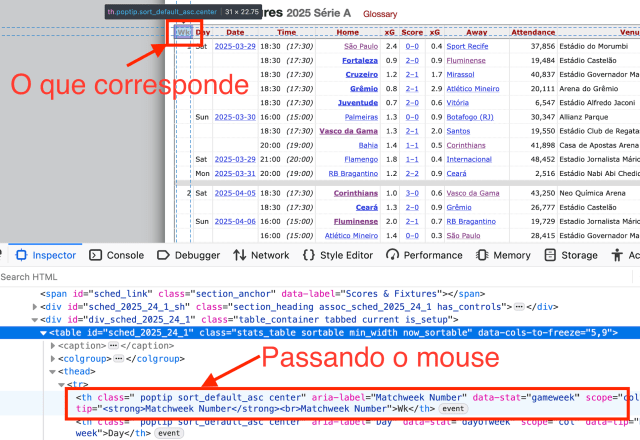
Você pode observar que todos os itens do cabeçalho começam com th. Mas você observará que é uma tabela de contingência. O que isso quer dizer? É uma tabela que tem os títulos das colunas na parte superior (o cabeçalho) e os títulos das linhas na primeira coluna.
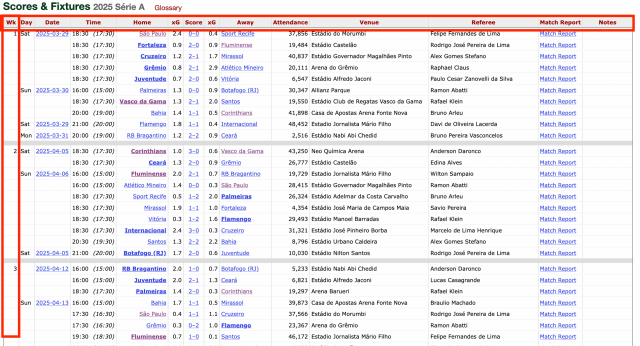
Poderíamos trabalhar assim. Mas para o que queremos fazer, é mais fácil trabalhar com a tabela unidimensional. Então vamos fazer o seguinte.
# iniciando uma lista vazia
cabecalho = []
for th in tabela.find_all('th')[:14]: # o [:14] só vai coletar o cabeçalho
cabecalho.append(th.text.strip())
Adicionando o [:14] depois do find_all fala para o Python só pegar os itens de 0 ou o primeiro à 14.
Raspando o Resto do Conteúdo
Para pegar o restante do conteúdo é um pouquinho mais complicado. Em uma linha da tabela você tem tr, th e varios td dentro do tr. Vamos precisar trabalhar cada um deles para pegar todos os jogos.
Cada linha da tabela é iniciada pelo tr (table row). Então vamos criar um loop para coletar toda informação dentro do tr. E vamos ter que criar outra loop para pegar todos os td e o th dentro do tr.
linhas = [] # lista para os dados
for tr in tabela.find_all('tr')[1:]: # elimina o cabeçalho
celulas = []
for td in tr.find_all(['td', 'th']):
celulas.append(td.text.strip())
linhas.append(celulas)
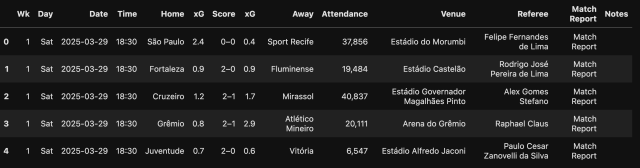
Temos todos os resultados, agora é só transformar esta informação em uma tabela de pandas para ficar mais fácil de ler.
jogos = pd.DataFrame(linhas, columns=cabecalho)
jogos.head()
Limpando os Dados
Os dados coletados tem alguns probleminhas, e vamos precisar dar uma limpada antes de fazer qualquer análise. Vamos começar olhando o tamanho da tabela.
jogos.shape
Você vai observar que o resultado é (420, 14). Se é um jogo por linha, nós sabemos que não tem 420 jogos no campeonato. Então tem mais linhas do que deve. Vamos descobrir o que está acontecendo.
Essa tabela é muito interessante. Eu sei que existem células sem dados. Contudo, se eu tentar encontrar essas células, não constaram como vazias.
jogos.isna().sum()
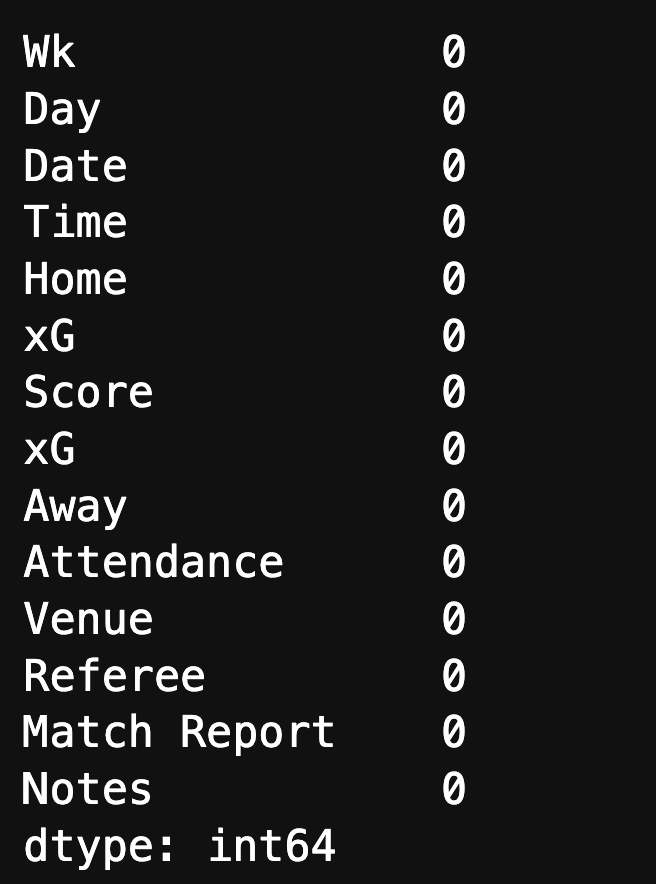
Mas, vou mostrar um truque de cientistas de dados para vocês. Tem uma diferença de NaN (not a number) que é um valor especial que representa dados ausentes ou nulos. Mas, nem todos os elementos vazios são ausentes ou nulos.
Para achar se tem a falta de um valor e não é considerado nulo, poderemos passar o seguinte código:
(jogos == '').sum()
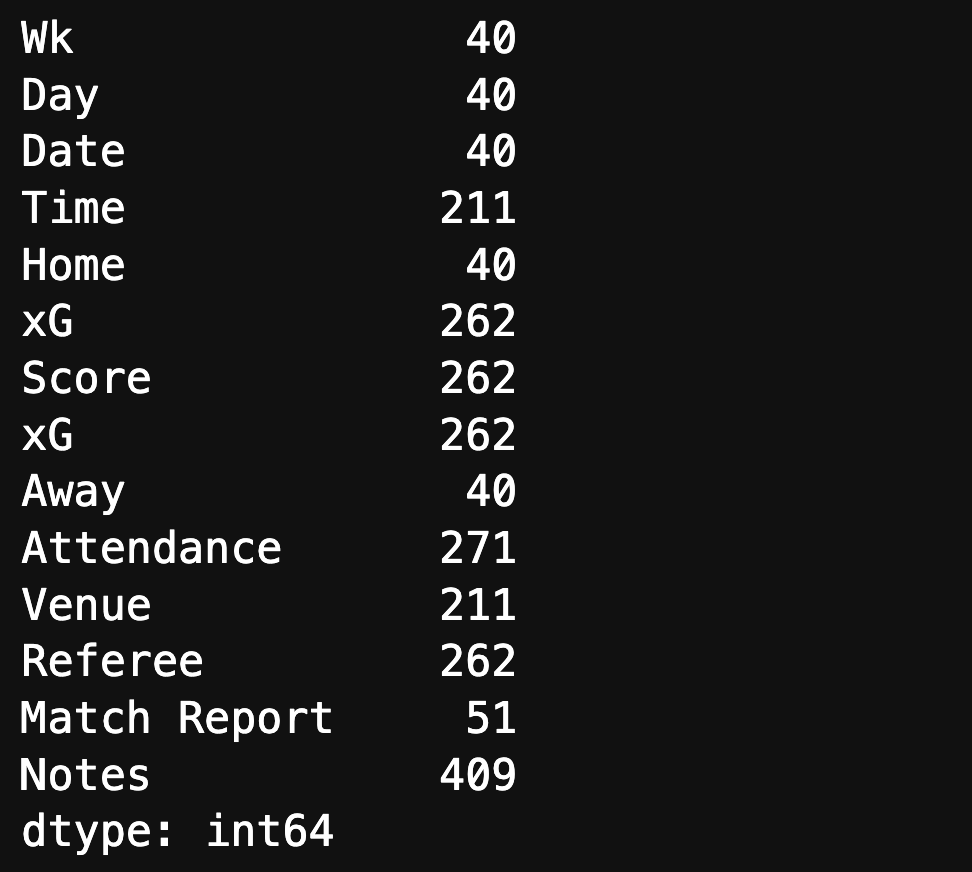
Esse resultado já mostra a realidade da nossa tabela. Tem várias maneiras de consertar esse problema. Eu vou demonstrar o mais simples.
jogos.replace("", pd.NA, inplace=True)
jogos.isna().sum()
Arrumando as Colunas
Se você ainda não observou, temos duas colunas com o mesmo nome xG. Isso acontece. Mas precisamos consertar isso antes que cause problemas em nossa análise.
Vamos adotar a maneira mais simples de fazer isso. Primeiro criamos uma lista com os nomes das colunas e mudamos os nomes usando o index. E falamos para o pandas usar a nova lista como colunas.
cols = list(jogos.columns)
cols[5] = "HxG"
cols[7] = "AxG"
jogos.columns = cols
Removendo os Dados Nulos
A parte final disso é remover os dados nulos. Mas não podemos aleatoriamente remover todos os nulos, pois lembre-se que os próximos jogos vão ser úteis para as nossas analises.
Observe que no Wk, há 40 resultados nulos. Isso significa que temos 40 linhas que são completamente em branco. Vamos remover essas linhas que não tem dados nenhum.
todos_jogos = jogos[jogos['Wk'].notna()]
Agora os nossos dados estão curados e prontos para ser analisados.
Comentários (0)
Seja o primeiro a comentar!
Deixe um comentário