
O pandas é uma ferramenta que já conhecemos. Já manipulamos dados em outros posts. Nesse artigo, vamos falar de uma das funcionalidades mais poderosas do pandas: o agrupamento de dados por períodos temporais.
Para ser sincero, trabalhar com datas pode ser um pouco intimidador no começo. Quando comecei a trabalhar com dados, me perdia entre timestamps, formato de datas e fusos horários. Contudo, uma vez que você domina as funções groupby() e resample(), você consegue extrair insights incríveis dos seus dados temporais.
De qualquer forma, você vai ver como é fácil transformar dados bagunçados em análises mensais claras e profissionais. Essa ferramenta é ideal para relatórios gerenciais, análise de tendências ou até dashboard de vendas.
O que é Agrupamento por Período?
O agrupamento por período é uma técnica que permite organizar seus dados por intervalos de tempo específicos. Isso é ideal para muitas coisas, vendas mensais por produto, crescimento de usuários por trimestre, gastos semanais por categoria, e por aí vai.
Ferramentas Necessárias
Todas as vezes que vamos fazer algum projeto de análise de dados, a minha recomendação é sempre Jupyter Notebook. O Spyder também é legal para isso. Contudo, o Jupyter é amplamente utilizado, e muitas empresas o usam.
Se você não tem ainda, ou precisa de uma refrescada na memória, você pode instalar diretamente, ou até usar o Google Collab que já vem com tudo configurado.
Instalando o Pandas
Antes de começar, você vai precisar instalar esse pacote, caso não tenha. Você pode instalar diretamente do Jupyter. Basta abrir uma célula e rodar o seguinte comando:
%pip install pandas
Rode a célula usando o Ctrl + Enter, ou simplesmente aperte o ▶. Isso vai instalar o pacote, ou você vai ver algo assim:
Quando tudo estiver pronto, podemos importar o pacote:
import pandas as pd
O pd não é necessário, mas fica mais fácil para escrever. Apelidando os pacotes é um método muito comum em Python. Mas, tome cuidado quando estiver apelidando as coisas, pode causar confusão. Mantenha os padrões do fabricante.
Criando os Dados
Como estamos aprendendo, vamos começar com uma coisa mais simples, antes de partir para algo mais complexo. Eu vou criar uma DataFrame com os dados de vendas para você ver como é fácil agrupar por período.
import pandas as pd
from datetime import datetime, timedelta
import numpy as np
# Criando dados fictícios de vendas
np.random.seed(42) # Para resultados consistentes
dates = pd.date_range('2024-01-01', '2024-12-31', freq='D')
vendas = np.random.randint(100, 1000, len(dates))
produtos = np.random.choice(['Pastel', 'Caldo de Cana', 'Fritas', 'Cerveja'], len(dates))
# Criando o DataFrame
df = pd.DataFrame({
'data': dates,
'vendas': vendas,
'produto': produtos
})
print(df.head())
data vendas produto
0 2024-01-01 202 Pastel
1 2024-01-02 535 Fritas
2 2024-01-03 960 Pastel
3 2024-01-04 370 Pastel
4 2024-01-05 206 Caldo de Cana
Ai está. Criei um DataFrame bem simples com tres colunas. Agora vamos agrupar esses dados por mês.
Código para Agrupar por Mês
Há dois métodos para fazer isso. Vamos começar com o groupby().
# Definindo a data como índice
df_indexed = df.set_index('data')
# Agrupando por mês
vendas_mensais = df_indexed.groupby(df_indexed.index.to_period('M'))['vendas'].sum()
print("Vendas mensais:")
print(vendas_mensais)
Deixa eu explicar o código com detalhes:
- set_index('data'): Esse comando define a coluna de data como índice do DataFrame.
- groupby(df_indexed.index.to_period('M')): Esse comando agrupa os dados por mês ('M').
- ['vendas'].sum(): Finalmente, esse comando soma as vendas de cada mês.
Código para Agrupar por Mês - resample()
Agora vamos usar um método similar que é o resample().
# Usando resample para agrupar por mês
vendas_mensais_resample = df_indexed.resample('M')['vendas'].sum()
print("Vendas mensais com resample:")
print(vendas_mensais_resample)
Você observa que é um método mais simples, mas que traz o mesmo resultado.
Agrupando por Diferentes Períodos
Digamos que o seu patrão quer ver vendas por semana ou trimestre. Também pode fazer com resample. Olha só:
# Vendas semanais
vendas_semanais = df_indexed.resample('W')['vendas'].sum()
# Vendas trimestrais
vendas_trimestrais = df_indexed.resample('Q')['vendas'].sum()
# Vendas por semestre
vendas_semestrais = df_indexed.resample('6M')['vendas'].sum()
print("Vendas semanais (primeiras 5):")
print(vendas_semanais.head())
print("\nVendas trimestrais:")
print(vendas_trimestrais)
Múltiplas Operações de Agregação
Às vezes você quer mais que apenas a soma. Você pode calcular várias estatísticas ao mesmo tempo:
# Múltiplas estatísticas mensais
estatisticas_mensais = df_indexed.resample('M')['vendas'].agg([
'sum', # total
'mean', # média
'count', # quantidade de registros
'min', # menor valor
'max' # maior valor
])
print("Estatísticas mensais completas:")
print(estatisticas_mensais)
Exemplo Completo e Profissional
Vamos usar um exemplo mais próximo da realidade. Criando os dados, vamos dar o exemplo completo.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Criando dados mais realistas
np.random.seed(42)
dates = pd.date_range('2023-01-01', '2024-12-31', freq='D')
# Simulando sazonalidade (mais vendas no final do ano)
base_sales = 500
seasonal_effect = 200 * np.sin(2 * np.pi * (dates.dayofyear - 300) / 365)
random_noise = np.random.normal(0, 100, len(dates))
vendas = base_sales + seasonal_effect + random_noise
vendas = np.maximum(vendas, 50) # Garantir vendas mínimas
# DataFrame final
df_completo = pd.DataFrame({
'data': dates,
'vendas': vendas,
'produto': np.random.choice(['A', 'B', 'C'], len(dates)),
'regiao': np.random.choice(['Norte', 'Sul', 'Leste', 'Oeste'], len(dates))
})
# Análise completa
df_completo = df_completo.set_index('data')
# 1. Vendas mensais totais
vendas_mensais = df_completo.resample('M')['vendas'].sum()
# 2. Análise por produto
vendas_por_produto = df_completo.groupby([
df_completo.index.to_period('M'),
'produto'
])['vendas'].sum().unstack(fill_value=0)
# 3. Crescimento mês a mês
crescimento = vendas_mensais.pct_change() * 100
print("=== RELATÓRIO MENSAL DE VENDAS ===")
print(f"\nTotal de vendas em 2024: R$ {vendas_mensais.sum():,.2f}")
print(f"Média mensal: R$ {vendas_mensais.mean():,.2f}")
print(f"Melhor mês: {vendas_mensais.idxmax()} (R$ {vendas_mensais.max():,.2f})")
print(f"Pior mês: {vendas_mensais.idxmin()} (R$ {vendas_mensais.min():,.2f})")
print("\nCrescimento mensal (últimos 6 meses):")
print(crescimento.tail(6).round(2))
Visualizando os Resultados
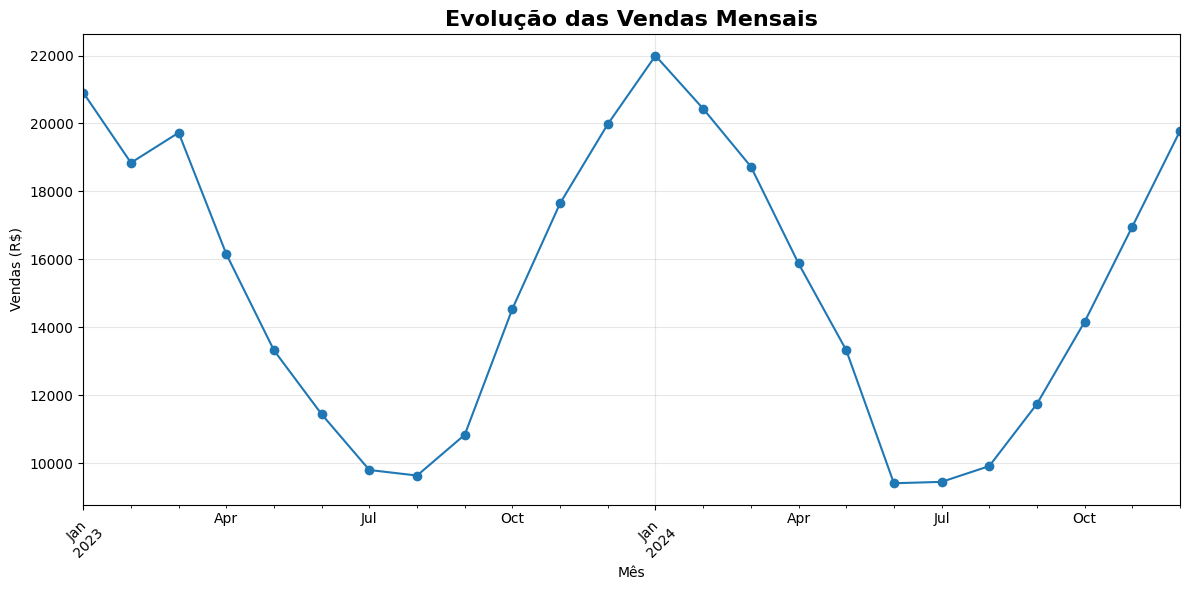
Vamos fazer um gráfico para ficar mais claro.
# Plotando as vendas mensais
plt.figure(figsize=(12, 6))
vendas_mensais.plot(kind='line', marker='o')
plt.title('Evolução das Vendas Mensais', fontsize=16, fontweight='bold')
plt.xlabel('Mês')
plt.ylabel('Vendas (R$)')
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
Salvando seus Resultados
Para salvar a análise como arquivo CSV:
# Salvando os resultados
vendas_mensais.to_csv('vendas_mensais.csv')
vendas_por_produto.to_csv('vendas_por_produto_mes.csv')
print("Arquivos salvos com sucesso!")
Conclusão
Agrupar dados por mês com pandas usando groupby() e resample() é mais simples do que parece. Com poucas linhas de código, você já consegue extrair insights poderosos dos seus dados temporais.
Em apenas alguns minutos, você aprendeu desde o básico até técnicas de agregação avançadas. Agora é só praticar com seus próprios dados de vendas, usuários ou qualquer série temporal!
Se você curtiu esse conteúdo, compartilhe com alguém que também está aprendendo análise de dados!
Comentários (0)
Seja o primeiro a comentar!
Deixe um comentário